Predis AI: Is This AI-Powered Tool Worth The Hype?
Apr 23, 2025


MetaCrawler has significantly contribute to the development of search engines during the mid-to-late 1990s and early 2000s but is often overlooked.
At its core, MetaCrawler is a meta-search engine that allows the user to search multiple search engines simultaneously.
Thereby generating comprehensive and diverse search results enough that a single search engine cannot give a better result.
To understand its significance and impact, it is only proper to reflect on its background. How it worked, and what made up its features with its lasting contribution to SEO and digital marketing.
MetaCrawler, launching in 1995 by the search technology firm Infoseek, which became part of the Disney conglomerate. It was designed based on the growing frustration during the early days of the Internet.
The search engines in use then only had a small scope and frequently failed to return comprehensive, accurate results. While major search engines such as AltaVista, Lycos, Yahoo, and later Google were indexing vast swaths of the web, they still could not provide the exhaustive search results needed for users to quickly find all the relevant information available online.
MetaCrawler emerged as a solution to this problem by allowing users to query multiple search engines simultaneously, aggregating the results into a single list. This meant a much broader, more diverse result set for search queries without requiring the user to manually execute the same query in different engines.
Although revolutionary for its time, MetaCrawler was released when the idea of a search engine was new. Search engines such as Yahoo were not search engines; they were much more directory sites with hand-curated lists of sites.
By the time MetaCrawler was developed, AltaVista and Yahoo had already automate web indexing. However, even these search engines had limitations in terms of the scope and quality of search results they could offer.
MetaCrawler emerged simultaneously with a more general trend in how people accessed the Internet. Users began demanding a more dynamic, efficient, and accurate method of finding content instead of relying on manually curated directories. MetaCrawler, by combining several engines into one interface, filled a gap that traditional search engines could not fill.

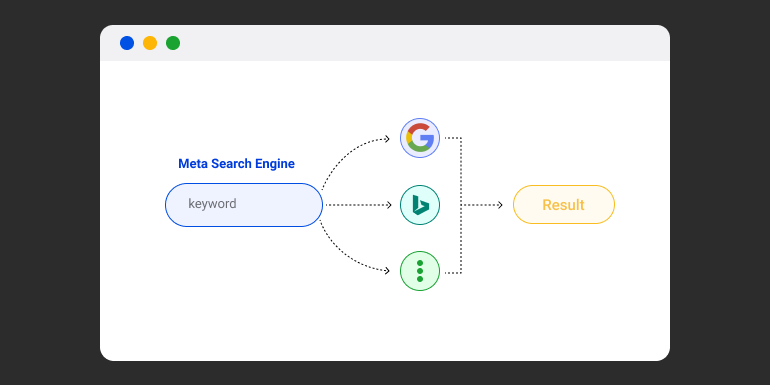
MetaCrawler is a meta-search tool with no particular database of Web pages in-house. It gathers search queries of its users and forwards them to other specified search engines-which are multiple and include Google, Yahoo, and AltaVista.
Amongst many others- and combines those search results to compile into an output, whereupon MetaCrawler delivers results. This can illustrate further below.
Forwarding the Query MetaCrawler forwards this query to a selection of other search engines. Examples include general-purpose search engines such as AltaVista, Lycos, etc. Depending on which other engines MetaCrawler is configuring to include in its searches.
Each search engine returns its results, which tend to be in slightly different orders. MetaCrawler aggregates the results and organizes them into one unified list. It attempts to filter out duplicate results and sometimes ranks them based on various factors like relevancy, prominence, or how frequently they appear across multiple search engines.
MetaCrawler presents this list to the user and provides links to relevant web pages from all the engines it queried. Unlike traditional search engines that rank results by complex algorithms according to factors like backlinks, keyword usage, and content relevance.
MetaCrawler focuses on bringing a broad range of results; often, it puts quantity and variety over precision. This aggregation method was very handy in the earlier days when the Internet was growing and could not index and rank the entire web accurately.

MetaCrawler offers several key features and services are highly valuable to internet users when the application first appear:
The greatest feature of MetaCrawler was that it presented search results from multiple search engines in one unified interface.
Users did not need to spend a lot of time and effort trying to manually search different engines for a complete set of results. It was, in fact, a “one-stop-shop” for web searches.
MetaCrawler had an extremely simple interface. There were no complicated filters or unnecessary options— just a search box and a results list. That was easy for novice users to find what they sought.
MetaCrawler provides more sophisticated search options for advanced users, including Boolean operators (AND, OR, NOT), phrase searches, and specific site searches. This allowed users to have more control over their search queries.
MetaCrawler also featured a web directory, similar to when Yahoo first started. The directory helps categorize websites under diverse topics and subtopics, assisting in seeking new sites or narrowing searches.
The interface on the results page was very clean and uncluttered, providing the results without too much advertising or other clutter. The system design is streamlined to focus on results rather than presenting extraneous information to users.
MetaCrawler also enabled searching in other languages and other regions of the world, making it available to anyone globally.
MetaCrawler’s approach to search was unique from the traditional search engines like Google, Yahoo, and AltaVista. Below is a comparison of MetaCrawler with the traditional search engines in several key areas:
Let’s check out the differences between classic search engines and metacrawler when it comes to database ownership.
Let’s check out the differences between classic search engines and metacrawler when it comes to ranking algorithms.
Let’s check out the differences between classic search engines and metacrawler when it comes to speed and relevance.
The accuracy was also low since the search came from different areas and might rank sites based on other criteria.
Let’s check out the differences between classic search engines and metacrawler when it comes to ad revenue model.
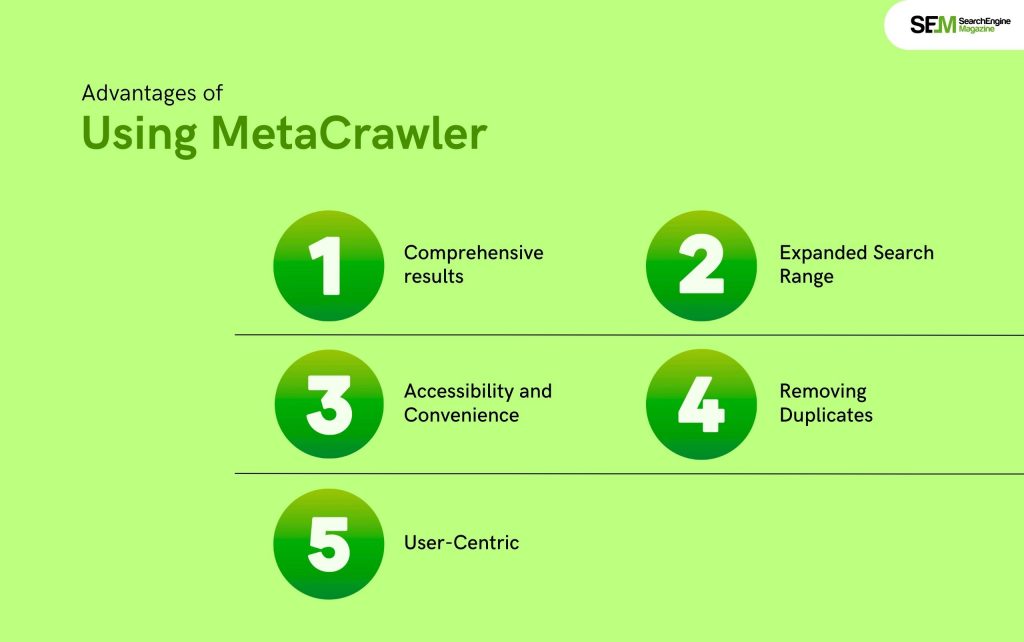
Although the flaws existed, MetaCrawler presented some attractive advantages for Internet users. At least during the early stage of the Internet:
MetaCrawler could aggregate the results of other search engines for the user. Thus, the user obtained a general view of the web through his or her results than with any other search engine.
Different search engines cataloged different parts of the web. The query of several search engines to a user meant that results would be shown from places. That may not have been included in a single search but may appear in another.
Many users were not interested in searching through different search engines. MetaCrawler provided a single-entry point for these users to access more comprehensive searches.
MetaCrawler tried to remove duplicate results. This was efficient compared to manually searching across many engines because the same result might appear several times.
MetaCrawler was centered on the user, aiming at delivering useful relevant search results quickly and in a form that could be easily understood.
We need to know about the limitations because that will help to understand the functionality of metacrawler.
Despite the innovativeness of MetaCrawler, it still had several challenges that impeded its sustainability and growth:
Because it aggregated results from multiple search engines, MetaCrawler was often slower than traditional search engines that maintained their indexes.
MetaCrawler’s results weren’t as refined or targeted as those of dedicated search engines. It lacked the sophisticated algorithms that search engines like Google developed over time to rank pages more accurately based on relevance.
MetaCrawler heavily depended on the search engines whose aggregated results. Whenever the algorithms change, any indexing practice changes. Changes in the APIs of those other search engines happen, and MetaCrawler’s functionality and output will be directly affected.
As Google and other search engines improved their algorithms and user experience, the necessity for a meta-search engine like MetaCrawler decreased. Google’s supremacy and the refinement of its indexing and ranking processes made MetaCrawler less important with time.

Why do you need to learn more about the significance of digital marketing along with SEO especially to gain more exposure? MetaCrawler had an indirect but profound impact on the SEO and digital marketing industries, especially in the early years:
Since MetaCrawler pulled results from various engines, getting backlinks from multiple search engines became the key to getting noticed. This early emphasis on backlinks shaped the direction of SEO practices. Especially in the concept of link building as a significant aspect of SEO.
Digital marketers learned to optimize their websites not only for Google but for other engines as well. MetaCrawler encourages webmasters to consider their visibility across various platforms, especially before Google’s dominance was fully established.
Affiliate marketing and sponsored listings is where MetaCrawler was headed-to be a prelude to the model that would later be used in search engines like Google when they monetized their services through pay-per-click advertising.
MetaCrawler was a harbinger of what was to come in the search world, providing a new solution to the fragmented and inefficient search environment of the mid-1990s.
It aggregated the results of numerous search engines. It provided users with a more extensive view of the web, overcoming some of the early challenges posed by search accuracy and completeness.
Although it faced significant limitations regarding speed, precision, and relevance, its impact on developing search technologies and digital marketing strategies was profound. While Google dominates the web search market nowadays with the maturity of the Internet, MetaCrawler still lost its market share, but now it is known as a historic part.
Nabamita Sinha loves to write about lifestyle and pop-culture. In her free time, she loves to watch movies and TV series and experiment with food. Her favorite niche topics are fashion, lifestyle, travel, and gossip content. Her style of writing is creative and quirky.
View all Posts
Predis AI: Is This AI-Powered Tool Worth The ...
Apr 23, 2025
Fliki AI: Is This AI-Powered Tool Worth The H...
Apr 22, 2025
Andi Search: Is This AI-Driven Search Engine ...
Apr 21, 2025
How To Retrieve Deleted Text Messages On Andr...
Apr 17, 2025
How To Know If Someone Blocked You On iMessag...
Apr 16, 2025